Ev ve Ofis taşıma sektöründe lider olmak.Teknolojiyi klrd takip ederek bunu müşteri menuniyeti amacı için kullanmak.Sektörde marka olmak.
İstanbul evden eve nakliyat
Misyonumuz sayesinde edindiğimiz müşteri memnuniyeti ve güven ile müşterilerimizin bizi tavsiye etmelerini sağlamak.
MVPNets: Multi-Viewing path deep learning neural networks for magnification invariant diagnosis in breast cancer
.png) This paper presents a deep learning network, called MVPNet and a customized data augmentation technique, called NuView, for magnification independent diagnosis. MVPNet is tailored to tackle the most common issues (diversity, relatively small size of datasets and manifestation of diagnostic biomarkers at various magnification levels) with breast cancer histology data to perform the classification. The network simultaneously analyzes local and global features of a given tissue image. It does so by viewing the tissue at varying levels of relative nuclei sizes. MVPNet has significantly less parameters than standard transfer learning deep models with comparable performance and it combines and processes local and global features simultaneously for effective diagnosis.
This paper presents a deep learning network, called MVPNet and a customized data augmentation technique, called NuView, for magnification independent diagnosis. MVPNet is tailored to tackle the most common issues (diversity, relatively small size of datasets and manifestation of diagnostic biomarkers at various magnification levels) with breast cancer histology data to perform the classification. The network simultaneously analyzes local and global features of a given tissue image. It does so by viewing the tissue at varying levels of relative nuclei sizes. MVPNet has significantly less parameters than standard transfer learning deep models with comparable performance and it combines and processes local and global features simultaneously for effective diagnosis.
KnowPain: Automated system for detecting pain in neonates from videos
.png) In this paper, a deep learning based approach is used to detect pain in videos of premature neonates during painful clinical procedures. A Conditional Generative Adversarial Network (CGAN) is used to continuously learn the representation and classify painful facial expressions in neonates from real and synthetic data. A Long Short-Term Memory (LSTM) is used for modeling the temporal changes in facial expression to further improve the classification. Furthermore, the proposed approach is able to implicitly learn the intensity of pain as a probability score directly from the facial expressions without any manual annotation.
In this paper, a deep learning based approach is used to detect pain in videos of premature neonates during painful clinical procedures. A Conditional Generative Adversarial Network (CGAN) is used to continuously learn the representation and classify painful facial expressions in neonates from real and synthetic data. A Long Short-Term Memory (LSTM) is used for modeling the temporal changes in facial expression to further improve the classification. Furthermore, the proposed approach is able to implicitly learn the intensity of pain as a probability score directly from the facial expressions without any manual annotation.
DEEPAGENT: An algorithm integration approach for person re-identification
.png) Person re-identification(RE-ID) has played a significant role in the fields of image processing and computer vision because of its potential value in practical applications. Researchers are striving to design new algorithms to improve the performance of RE-ID but ignore the advantages of existing approaches. In this paper, motivated by deep reinforcement learning, we propose a Deep Agent, which can integrate existing algorithms and enable them to complement each other. Two Deep Agents are designed to integrate algorithms for data augmentation and feature extraction parts separately for RE-ID. Experiment results demonstrate that the integrated algorithms can achieve a better accuracy than using each one of them alone.
Person re-identification(RE-ID) has played a significant role in the fields of image processing and computer vision because of its potential value in practical applications. Researchers are striving to design new algorithms to improve the performance of RE-ID but ignore the advantages of existing approaches. In this paper, motivated by deep reinforcement learning, we propose a Deep Agent, which can integrate existing algorithms and enable them to complement each other. Two Deep Agents are designed to integrate algorithms for data augmentation and feature extraction parts separately for RE-ID. Experiment results demonstrate that the integrated algorithms can achieve a better accuracy than using each one of them alone.
Patch-based latent fingerprint matching using deep learning
.png) This paper presents an approach for matching latent to rolled fingerprints using the (a) similarity of learned representations of patches and (b) the minutiae on the correlated patches. A deep learning network is used to learn optimized representations of image patches. Similarity scores between patches from the latent and reference fingerprints are determined using a distance metric learned with a convolutional neural network. The matching score is obtained by fusing the patch and minutiae similarity scores.
This paper presents an approach for matching latent to rolled fingerprints using the (a) similarity of learned representations of patches and (b) the minutiae on the correlated patches. A deep learning network is used to learn optimized representations of image patches. Similarity scores between patches from the latent and reference fingerprints are determined using a distance metric learned with a convolutional neural network. The matching score is obtained by fusing the patch and minutiae similarity scores.
An unbiased temporal representation for video-based person re-identification
.png) In the re-id task, the long-term dependency is quite common since the key information (identity of the pedestrian) exists most of the time along the given sequence. Thus, the importance of a frame should not be determined by its position in a sequence, which is usually biased in state-of-the-art models with RNNs. In this paper, we argue that long-term dependency can be very important and propose an unbiased siamese recurrent convolutional neural network architecture to model and associate pedestrians in a video. Experimental results on two public datasets demonstrate the effectiveness of the proposed method.
In the re-id task, the long-term dependency is quite common since the key information (identity of the pedestrian) exists most of the time along the given sequence. Thus, the importance of a frame should not be determined by its position in a sequence, which is usually biased in state-of-the-art models with RNNs. In this paper, we argue that long-term dependency can be very important and propose an unbiased siamese recurrent convolutional neural network architecture to model and associate pedestrians in a video. Experimental results on two public datasets demonstrate the effectiveness of the proposed method.
HESCNET: A synthetically pre-trained convolutional neural network for human embryonic stem cell colony classification
.png) This paper proposes a method for improving the results of deep convolutional neural network classification using synthetic image samples. Generative adversarial networks are used to generate synthetic images from a dataset of phase contrast, human embryonic stem cell (hESC) microscopy images. hESCnet, a deep convolutional neural network is trained, and the results are shown on various combinations of synthetic and real images in order to improve the classification results with minimal data.
This paper proposes a method for improving the results of deep convolutional neural network classification using synthetic image samples. Generative adversarial networks are used to generate synthetic images from a dataset of phase contrast, human embryonic stem cell (hESC) microscopy images. hESCnet, a deep convolutional neural network is trained, and the results are shown on various combinations of synthetic and real images in order to improve the classification results with minimal data.
Multi-label classification of stem cell microscopy images using deep learning
.png) This paper develops a pattern recognition and machine learning system to localize cell colony subtypes in multi-label, phase-contrast microscopy images. A convolutional neural network is trained to recognize homogeneous cell colonies, and is used in a sliding-window patch based testing method to localize these homogeneous cell types within heterogeneous, multi-label images. The method is used to determine the effects of nicotine on induced pluripotent stem cells expressing the Huntington’s disease phenotype. The results of the network are compared to those of an ECOC classifier trained on texture features.
This paper develops a pattern recognition and machine learning system to localize cell colony subtypes in multi-label, phase-contrast microscopy images. A convolutional neural network is trained to recognize homogeneous cell colonies, and is used in a sliding-window patch based testing method to localize these homogeneous cell types within heterogeneous, multi-label images. The method is used to determine the effects of nicotine on induced pluripotent stem cells expressing the Huntington’s disease phenotype. The results of the network are compared to those of an ECOC classifier trained on texture features.
DeepDriver: Automated system for measuring valence and arousal in car driver videos
.png) We develop an automated system for analyzing facial expressions using valence and arousal measurements of a car driver. Our approach is a data driven approach and does not include any pre-processing done to the faces of the drivers. The motivation of this paper is to show that with large amount of data, deep learning networks can extract better and more robust facial features compared to state of-the-art hand crafted features. The network was trained on just the raw facial images and achieves better results compared to state-of-the-art methods. Our system incorporates Convolutional Neural Networks (CNN) for detecting the face and extracting the facial features, and a Long Short Term Memory (LSTM) for modelling the changes in CNN features with respect to time.
We develop an automated system for analyzing facial expressions using valence and arousal measurements of a car driver. Our approach is a data driven approach and does not include any pre-processing done to the faces of the drivers. The motivation of this paper is to show that with large amount of data, deep learning networks can extract better and more robust facial features compared to state of-the-art hand crafted features. The network was trained on just the raw facial images and achieves better results compared to state-of-the-art methods. Our system incorporates Convolutional Neural Networks (CNN) for detecting the face and extracting the facial features, and a Long Short Term Memory (LSTM) for modelling the changes in CNN features with respect to time.
DeephESC: An automated system for generating and classification of human embryonic stem cells
.png) In this paper, we introduce a hierarchical classification system consisting of Convolutional Neural Networks (CNN) and Triplet CNN’s to classify hESC images into six different classes. We also design an ensemble of Generative Adversarial Networks (GAN) for generating synthetic images of hESC’s. We validate the quality of the generated hESC images by training all of our CNN’s exclusively on the synthetic images generated by the GAN’s and evaluating them on the original hESC images.
In this paper, we introduce a hierarchical classification system consisting of Convolutional Neural Networks (CNN) and Triplet CNN’s to classify hESC images into six different classes. We also design an ensemble of Generative Adversarial Networks (GAN) for generating synthetic images of hESC’s. We validate the quality of the generated hESC images by training all of our CNN’s exclusively on the synthetic images generated by the GAN’s and evaluating them on the original hESC images.
Soccer: Who has the ball? Generating visual analytics and player statistics
.png) In this paper, we propose an approach that automatically generates visual analytics from videos specifically for soccer to help coaches and recruiters identify the most promising talents. We use (a) Convolutional Neural Networks (CNNs) to localize soccer players in a video and identify players controlling the ball, (b) Deep Convolutional Generative Adversarial Networks (DCGAN) for data augmentation, (c) a histogram based matching to identify teams and (d) frame-by-frame prediction and verification analyses to generate visual analytics.
In this paper, we propose an approach that automatically generates visual analytics from videos specifically for soccer to help coaches and recruiters identify the most promising talents. We use (a) Convolutional Neural Networks (CNNs) to localize soccer players in a video and identify players controlling the ball, (b) Deep Convolutional Generative Adversarial Networks (DCGAN) for data augmentation, (c) a histogram based matching to identify teams and (d) frame-by-frame prediction and verification analyses to generate visual analytics.
Latent fingerprint image quality assessment using deep learning
.png) Latent fingerprints are fingerprint impressions unintentionally left on surfaces at a crime scene. They are crucial in crime scene investigations for making identifications or exclusions of suspects. Determining the quality of latent fingerprint images is crucial to the effectiveness and reliability of matching algorithms. To alleviate the inconsistency and subjectivity inherent in feature markups by latent fingerprint examiners, automatic processing of latent fingerprints is imperative. We propose a deep neural network that predicts the quality of image patches extracted from a latent fingerprint and knits them together to predict the quality of a given latent fingerprint.
Latent fingerprints are fingerprint impressions unintentionally left on surfaces at a crime scene. They are crucial in crime scene investigations for making identifications or exclusions of suspects. Determining the quality of latent fingerprint images is crucial to the effectiveness and reliability of matching algorithms. To alleviate the inconsistency and subjectivity inherent in feature markups by latent fingerprint examiners, automatic processing of latent fingerprints is imperative. We propose a deep neural network that predicts the quality of image patches extracted from a latent fingerprint and knits them together to predict the quality of a given latent fingerprint.
On The Accuracy and Robustness of Deep Triplet Embedding for Fingerprint Liveness Detection
.png) Liveness detection is an anti-spoofing technique for dealing with presentation attacks on biometrics authentication systems. Since biometrics are usually visible to everyone, they can be easily captured by a malignant user and replicated to steal someone’s identity. In this paper, the classical binary classification formulation (live/fake) is substituted by a deep metric learning framework that can generate a representation of real and artificial fingerprints and explicitly models the underlying factors that explain their interand intra-class variations. The framework is based on a deep triplet network architecture and consists of a variation of the original triplet loss function. Experiments show that the approach can perform liveness detection in real-time outperforming the state-of-the-art on several benchmark datasets.
Liveness detection is an anti-spoofing technique for dealing with presentation attacks on biometrics authentication systems. Since biometrics are usually visible to everyone, they can be easily captured by a malignant user and replicated to steal someone’s identity. In this paper, the classical binary classification formulation (live/fake) is substituted by a deep metric learning framework that can generate a representation of real and artificial fingerprints and explicitly models the underlying factors that explain their interand intra-class variations. The framework is based on a deep triplet network architecture and consists of a variation of the original triplet loss function. Experiments show that the approach can perform liveness detection in real-time outperforming the state-of-the-art on several benchmark datasets.
Novel Representation for Driver Emotion Recognition in Motor Vehicle Videos
.png) A novel feature representation of human facial expressions for emotion recognition is developed. The representation leveraged the background texture removal ability of Anisotropic Inhibited Gabor Filtering (AIGF) with the compact representation of spatiotemporal local binary patterns. The emotion recognition system incorporated face detection and registration followed by the proposed feature representation: Local Anisotropic Inhibited Binary Patterns in Three Orthogonal Planes (LAIBP-TOP) and classification. The system is evaluated on videos from Motor Trend Magazine’s Best Driver Car of the Year 2014-2016. The results showed improved performance compared to other state-of-the-art feature representations.
A novel feature representation of human facial expressions for emotion recognition is developed. The representation leveraged the background texture removal ability of Anisotropic Inhibited Gabor Filtering (AIGF) with the compact representation of spatiotemporal local binary patterns. The emotion recognition system incorporated face detection and registration followed by the proposed feature representation: Local Anisotropic Inhibited Binary Patterns in Three Orthogonal Planes (LAIBP-TOP) and classification. The system is evaluated on videos from Motor Trend Magazine’s Best Driver Car of the Year 2014-2016. The results showed improved performance compared to other state-of-the-art feature representations.
Attributes Co-occurrence Pattern Mining for Video-Based Person Re-identification
.png) In this paper, a new way to take advantage of image processing, computer vision and pattern recognition is proposed. First, convolutional neural networks are adopted to detect the attributes. Second, the dependencies among attributes are obtained by mining association rules, and they are used to refine the attributes classification results. Third, metric learning technique is used to transfer the attribute learning task to person re-identification. Finally, the approach is integrated into an appearance-based method for video-based person re-identification. Experimental results on two benchmark datasets indicate that attributes can provide improvements both in accuracy and generalization capabilities.
In this paper, a new way to take advantage of image processing, computer vision and pattern recognition is proposed. First, convolutional neural networks are adopted to detect the attributes. Second, the dependencies among attributes are obtained by mining association rules, and they are used to refine the attributes classification results. Third, metric learning technique is used to transfer the attribute learning task to person re-identification. Finally, the approach is integrated into an appearance-based method for video-based person re-identification. Experimental results on two benchmark datasets indicate that attributes can provide improvements both in accuracy and generalization capabilities.
EDeN: Ensemble of deep networks for vehicle classification
.png) Traffic surveillance has always been a challenging task to automate. The main difficulties arise from the high variation of the vehicles appertaining to the same category, low resolution, changes in illumination and occlusions. Due to the lack of large labeled datasets, deep learning techniques still have not shown their full potential. In this paper, thanks to the MIOvision Traffic Camera Dataset (MIO-TCD), an Ensemble of Deep Networks (EDeN) is used to successfully classify surveillance images into eleven different classes of vehicles. The ensemble of deep networks consists of 2 individual networks that are trained independently. Experimental results show that the ensemble of networks gives better performance compared to individual networks and it is robust to noise. The ensemble of networks achieves an accuracy of 97.80%, mean precision of 94.39%, mean recall of 91.90% and Cohen kappa of 96.58.
Traffic surveillance has always been a challenging task to automate. The main difficulties arise from the high variation of the vehicles appertaining to the same category, low resolution, changes in illumination and occlusions. Due to the lack of large labeled datasets, deep learning techniques still have not shown their full potential. In this paper, thanks to the MIOvision Traffic Camera Dataset (MIO-TCD), an Ensemble of Deep Networks (EDeN) is used to successfully classify surveillance images into eleven different classes of vehicles. The ensemble of deep networks consists of 2 individual networks that are trained independently. Experimental results show that the ensemble of networks gives better performance compared to individual networks and it is robust to noise. The ensemble of networks achieves an accuracy of 97.80%, mean precision of 94.39%, mean recall of 91.90% and Cohen kappa of 96.58.
Iris liveness detection by relative distance comparisons
.png) The focus of this paper is on presentation attack detection for the iris biometrics, which measures the pattern within the colored concentric circle of the subjects’ eyes, to authenticate an individual to a generic user verification system. Unlike previous deep learning methods that use single convolutional neural network architectures, this paper develops a framework built upon triplet convolutional networks that takes as input two real iris patches and a fake patch or two fake patches and a genuine patch. The smaller architecture provides a way to do early stopping based on the liveness of single patches rather than the whole image. The matching is performed by computing the distance with respect to a reference set of real and fake examples. The proposed approach allows for realtime processing using a smaller network and provides equal or better than state-of-the-art performance on three benchmark datasets of photo-based and contact lens presentation attacks.
The focus of this paper is on presentation attack detection for the iris biometrics, which measures the pattern within the colored concentric circle of the subjects’ eyes, to authenticate an individual to a generic user verification system. Unlike previous deep learning methods that use single convolutional neural network architectures, this paper develops a framework built upon triplet convolutional networks that takes as input two real iris patches and a fake patch or two fake patches and a genuine patch. The smaller architecture provides a way to do early stopping based on the liveness of single patches rather than the whole image. The matching is performed by computing the distance with respect to a reference set of real and fake examples. The proposed approach allows for realtime processing using a smaller network and provides equal or better than state-of-the-art performance on three benchmark datasets of photo-based and contact lens presentation attacks.
Multi-person tracking by online learned grouping model with non-linear motion context
.png) Associating tracks in different camera views directly based on their appearance similarity is difficult and prone to error. In most previous methods, the appearance similarity is computed either using color histograms or based on pretrained brightness transfer function that maps color between cameras. In this paper, a novel reference set based appearance model is proposed to improve multitarget tracking in a network of nonoverlapping cameras. Contrary to previous work, a reference set is constructed for a pair of cameras, containing subjects appearing in both camera views. The effectiveness of the proposed method over the state of the art on two challenging real-world multicamera video data sets is demonstrated by thorough experiments.
Associating tracks in different camera views directly based on their appearance similarity is difficult and prone to error. In most previous methods, the appearance similarity is computed either using color histograms or based on pretrained brightness transfer function that maps color between cameras. In this paper, a novel reference set based appearance model is proposed to improve multitarget tracking in a network of nonoverlapping cameras. Contrary to previous work, a reference set is constructed for a pair of cameras, containing subjects appearing in both camera views. The effectiveness of the proposed method over the state of the art on two challenging real-world multicamera video data sets is demonstrated by thorough experiments.
Selective experience replay in reinforcement learning for re-identification
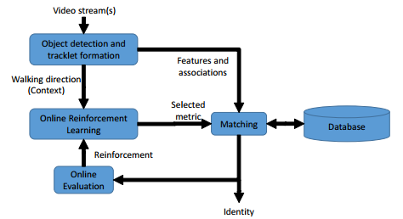 Person reidentification has the problem of recognizing a person across non-overlapping camera views. Pose variations, illumination conditions, low resolution images, and occlusion were the main challenges encountered in reidentification. Due to the uncontrolled environment in which the videos were captured, people could appear in different poses and the appearance of a person could vary significantly. The walking direction of a person provided a good estimation of their pose. Therefore, proposed is a reidentification system which adaptively selected an appropriate distance metric based on context of walking direction using reinforcement learning. Though experiments, it was showed that such a dynamic strategy outperformed static strategy learned or designed offline
Person reidentification has the problem of recognizing a person across non-overlapping camera views. Pose variations, illumination conditions, low resolution images, and occlusion were the main challenges encountered in reidentification. Due to the uncontrolled environment in which the videos were captured, people could appear in different poses and the appearance of a person could vary significantly. The walking direction of a person provided a good estimation of their pose. Therefore, proposed is a reidentification system which adaptively selected an appropriate distance metric based on context of walking direction using reinforcement learning. Though experiments, it was showed that such a dynamic strategy outperformed static strategy learned or designed offline
People tracking in camera networks: Three open questions
.png) The Boston incident underlines the need for more in-depth research on how to keep tabs on the location and identity of dynamic objects in a scene, which is foundational to automatic video analysis for applications such as surveillance, monitoring, and behavioral analysis. Research into tracking people in a single-camera view has matured enough to produce reliable solutions, and smart camera networks are sparking interest in tracking across multiple-camera views. However, tracking in this context has many more challenges than in a single view. When networked cameras have partially overlapping views, spatiotemporal constraints enable tracking, but in larger camera networks, overlap is often impractical, and appearance is the key tracking enabler.
The Boston incident underlines the need for more in-depth research on how to keep tabs on the location and identity of dynamic objects in a scene, which is foundational to automatic video analysis for applications such as surveillance, monitoring, and behavioral analysis. Research into tracking people in a single-camera view has matured enough to produce reliable solutions, and smart camera networks are sparking interest in tracking across multiple-camera views. However, tracking in this context has many more challenges than in a single view. When networked cameras have partially overlapping views, spatiotemporal constraints enable tracking, but in larger camera networks, overlap is often impractical, and appearance is the key tracking enabler.
An online learned elementary grouping model for multi-target tracking
.png) We introduce an online approach to learn possible elementary for inferring high level context that can be used to improve multi-target tracking in a data-association based framework. Unlike most existing association-based tracking approaches that use only low level information to build the affinity model and consider each target as an independent agent, we online learn social grouping behavior to provide additional information for producing more robust tracklets affinities. Social grouping behavior of pairwise targets is first learned from confident tracklets and encoded in a disjoint grouping graph. The grouping graph is further completed with the help of group tracking. The proposed method is efficient, handles group merge and split, and can be easily integrated into any basic affinity model. We evaluate our approach on two public datasets, and show significant improvements compared with state-of-the-art methods.
We introduce an online approach to learn possible elementary for inferring high level context that can be used to improve multi-target tracking in a data-association based framework. Unlike most existing association-based tracking approaches that use only low level information to build the affinity model and consider each target as an independent agent, we online learn social grouping behavior to provide additional information for producing more robust tracklets affinities. Social grouping behavior of pairwise targets is first learned from confident tracklets and encoded in a disjoint grouping graph. The grouping graph is further completed with the help of group tracking. The proposed method is efficient, handles group merge and split, and can be easily integrated into any basic affinity model. We evaluate our approach on two public datasets, and show significant improvements compared with state-of-the-art methods.
Context-aware reinforcement learning for re-identification in a video network
.png) Re-identification of people in a large camera network has gained popularity in recent years. The problem still remains challenging due to variations across cameras. A variety of techniques which concentrate on either features or matching have been proposed. Similar to majority of computer vision approaches, these techniques use fixed features and/or parameters. As the operating conditions of a vision system change, its performance deteriorates as fixed features and/or parameters are no longer suited for the new conditions. We propose to use context-aware reinforcement learning to handle this challenge. We capture the changing operating conditions through context and learn mapping between context and feature weights to improve the re-identification accuracy. The results are shown using videos from a camera network that consists of eight cameras.
Re-identification of people in a large camera network has gained popularity in recent years. The problem still remains challenging due to variations across cameras. A variety of techniques which concentrate on either features or matching have been proposed. Similar to majority of computer vision approaches, these techniques use fixed features and/or parameters. As the operating conditions of a vision system change, its performance deteriorates as fixed features and/or parameters are no longer suited for the new conditions. We propose to use context-aware reinforcement learning to handle this challenge. We capture the changing operating conditions through context and learn mapping between context and feature weights to improve the re-identification accuracy. The results are shown using videos from a camera network that consists of eight cameras.
|


